
データはあるが十分な学習ができない ― 金融リスクを扱うふたつの壁
不正取引、融資の延滞やデフォルト、マネー・ローンダリングの兆候――。
金融機関が日々向き合っているリスク事象の多くは、発生頻度が高くありません。しかし、その「まれさ」こそが、経営にとっては大きなインパクトを持ちます。わずかな不正を見逃せば損失につながり、与信判断を誤れば将来の不良債権リスクに直結します。だからこそ、多くの金融機関がAIや機械学習を活用した高度なリスク管理モデルの構築に取り組んでいます。
ところが現場では、こんな声も少なくありません。
「データは十分に蓄積されているはずなのに、思うようにモデルができない」。
背景には、データの質と扱いに関するふたつの壁があります。
ひとつ目の壁:データの不均衡
金融に限らずリスク事象はデータ全体から見ればごく少数です。金融での不正取引も、デフォルトも、全取引・全契約のなかでは一部に過ぎません。その結果、学習データは極端に偏ります。多数を占める“正常”データにモデルが引きずられ、肝心の異常パターンを十分に捉えられないことは多くあります。これは、不正検知でも与信モデルでも共通する構造的な課題です。
ふたつ目の壁:データ共有の制約
もうひとつは、データの扱いに関する制約です。金融データの多くは、顧客属性や取引履歴などを含む構造化されたテーブルデータであり、個人情報保護法や、金融分野固有の規制、社内規程のもとで厳格に管理されています。部門横断での活用や、外部パートナーとの共同開発も簡単ではありません。
このふたつの壁は、それぞれ独立しているようでいて、実務の現場では連続して立ちはだかります。「不均衡だからデータを増やしたい」ということに思い至っても、「簡単には共有できない」という現実に直面することになります。
金融機関が日々向き合っているリスク事象の多くは、発生頻度が高くありません。しかし、その「まれさ」こそが、経営にとっては大きなインパクトを持ちます。わずかな不正を見逃せば損失につながり、与信判断を誤れば将来の不良債権リスクに直結します。だからこそ、多くの金融機関がAIや機械学習を活用した高度なリスク管理モデルの構築に取り組んでいます。
ところが現場では、こんな声も少なくありません。
「データは十分に蓄積されているはずなのに、思うようにモデルができない」。
背景には、データの質と扱いに関するふたつの壁があります。
ひとつ目の壁:データの不均衡
金融に限らずリスク事象はデータ全体から見ればごく少数です。金融での不正取引も、デフォルトも、全取引・全契約のなかでは一部に過ぎません。その結果、学習データは極端に偏ります。多数を占める“正常”データにモデルが引きずられ、肝心の異常パターンを十分に捉えられないことは多くあります。これは、不正検知でも与信モデルでも共通する構造的な課題です。
ふたつ目の壁:データ共有の制約
もうひとつは、データの扱いに関する制約です。金融データの多くは、顧客属性や取引履歴などを含む構造化されたテーブルデータであり、個人情報保護法や、金融分野固有の規制、社内規程のもとで厳格に管理されています。部門横断での活用や、外部パートナーとの共同開発も簡単ではありません。
このふたつの壁は、それぞれ独立しているようでいて、実務の現場では連続して立ちはだかります。「不均衡だからデータを増やしたい」ということに思い至っても、「簡単には共有できない」という現実に直面することになります。
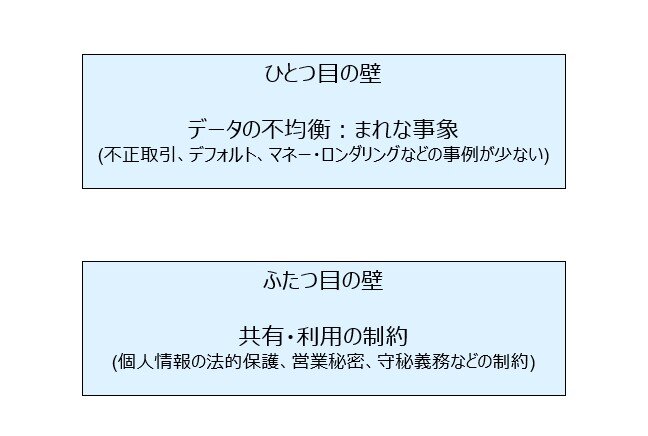
図1:金融リスクデータの扱いを困難にするふたつの壁
データはある。だが、学習に最適な形では使えない。
この構造をどう乗り越えるかが、金融機関におけるリスクに取り組むAI活用の鍵になるのです。
この構造をどう乗り越えるかが、金融機関におけるリスクに取り組むAI活用の鍵になるのです。
“増やす”という方法 ― まれな金融リスクを効果的に学習する
ひとつ目の壁である「データの不均衡」に対して、どのようなアプローチがあるのでしょうか。
たとえば、クレジットカードの不正取引、住宅ローンやカードローンの延滞・デフォルト、あるいはマネー・ローンダリングの兆候などを予測したり検出したりするニーズは常に存在しています。いずれも、実際の発生件数はごくわずかです。その結果、AIモデルの学習データは「正常取引・正常返済パターン」に偏りがちで、リスク事象を精緻に捉えられないという課題があります。
もっとも単純な対応として、少数のデータをコピーして“量だけ増やす”方法が考えられます。しかし、同じデータを繰り返し使っても、モデルは真に多様なパターンを捉えられません。そこで登場するのが、「オーバーサンプリング」という考え方です。これは、少数クラスのデータを人工的に増やすことで、学習バランスを改善する手法です。
2019年に発表された、CTGAN(Conditional Tabular GAN)のような生成モデルが、金融のテーブルデータにも適用されつつあります。CTGANは、GAN(敵対的生成ネットワーク)の枠組みをテーブルデータに適用したもので、構造化データに含まれる数値・カテゴリ情報を同時に扱える点が特徴です。
詳細な技術情報は、著名なAIの国際会議NeurIPSで発表された論文 Modeling Tabular Data using Conditional GAN で確認できます。
https://papers.neurips.cc/paper/8953-modeling-tabular-data-using-conditional-gan.pdf
GANは、偽物データを生成する「生成モデル」と、そのデータが本物か偽物かを見破ろうとする「識別モデル」が互いに競い合いながら学習します。CTGANはここに「条件付き生成(Conditional Generation)」を取り入れることで、特定の条件に応じたデータ生成――たとえば「デフォルト発生ケースだけを増やす」――が可能になります。こうした仕組みによって、単純な複製では得られない“多様で利用可能なサンプル”を生み出せるのです。
実装面では、オープンソースのライブラリとして CTGAN(Pythonパッケージ) が公開されています。
https://pypi.org/project/ctgan/
また、このライブラリはSDV(Synthetic Data Vault)の一部として提供されており、複数の生成手法や検証ツールとあわせて使うこともできます。
具体的な活用例としては、
・不正検知モデルの学習データ拡充:少数の不正事例を増やし、検知感度を改善
・与信モデルの精度向上:まれな高リスク事例を補完し、予測精度を向上
・極端な経済状況を想定したシナリオ検証:景気後退や特定業種の業績悪化といった“通常はあまり起きない状況”を想定し、そのとき融資全体にどの程度の延滞や損失が発生しうるかを事前にシミュレーションする
などがあげられます。
これは、規制対応や資本計画の精緻化にもつながるテーマであり、合成データはその裏側を支える技術になりえます。
たとえば、クレジットカードの不正取引、住宅ローンやカードローンの延滞・デフォルト、あるいはマネー・ローンダリングの兆候などを予測したり検出したりするニーズは常に存在しています。いずれも、実際の発生件数はごくわずかです。その結果、AIモデルの学習データは「正常取引・正常返済パターン」に偏りがちで、リスク事象を精緻に捉えられないという課題があります。
もっとも単純な対応として、少数のデータをコピーして“量だけ増やす”方法が考えられます。しかし、同じデータを繰り返し使っても、モデルは真に多様なパターンを捉えられません。そこで登場するのが、「オーバーサンプリング」という考え方です。これは、少数クラスのデータを人工的に増やすことで、学習バランスを改善する手法です。
2019年に発表された、CTGAN(Conditional Tabular GAN)のような生成モデルが、金融のテーブルデータにも適用されつつあります。CTGANは、GAN(敵対的生成ネットワーク)の枠組みをテーブルデータに適用したもので、構造化データに含まれる数値・カテゴリ情報を同時に扱える点が特徴です。
詳細な技術情報は、著名なAIの国際会議NeurIPSで発表された論文 Modeling Tabular Data using Conditional GAN で確認できます。
https://papers.neurips.cc/paper/8953-modeling-tabular-data-using-conditional-gan.pdf
GANは、偽物データを生成する「生成モデル」と、そのデータが本物か偽物かを見破ろうとする「識別モデル」が互いに競い合いながら学習します。CTGANはここに「条件付き生成(Conditional Generation)」を取り入れることで、特定の条件に応じたデータ生成――たとえば「デフォルト発生ケースだけを増やす」――が可能になります。こうした仕組みによって、単純な複製では得られない“多様で利用可能なサンプル”を生み出せるのです。
実装面では、オープンソースのライブラリとして CTGAN(Pythonパッケージ) が公開されています。
https://pypi.org/project/ctgan/
また、このライブラリはSDV(Synthetic Data Vault)の一部として提供されており、複数の生成手法や検証ツールとあわせて使うこともできます。
具体的な活用例としては、
・不正検知モデルの学習データ拡充:少数の不正事例を増やし、検知感度を改善
・与信モデルの精度向上:まれな高リスク事例を補完し、予測精度を向上
・極端な経済状況を想定したシナリオ検証:景気後退や特定業種の業績悪化といった“通常はあまり起きない状況”を想定し、そのとき融資全体にどの程度の延滞や損失が発生しうるかを事前にシミュレーションする
などがあげられます。
これは、規制対応や資本計画の精緻化にもつながるテーマであり、合成データはその裏側を支える技術になりえます。
“減らす”という方法 ― 境界ケースを残しつつ多数データを整理する
先ほどは、まれなリスク事象を増やす発想としてCTGANなどのデータの合成技術を紹介しましたが、もうひとつの選択肢として「多数派データを整理する」という戦略もあります。これは、データ全体の“バランス”を取る発想です。
たとえば、新規融資案件を評価するモデルを考えてみましょう。多くのケースは正常に返済されていますが、債務超過や業況悪化で返済が滞るなど返済に対する異常ケースはまれにしか存在しません。このような不均衡なデータをそのまま学習に使うと、モデルは“安全側に判断するバイアス”を強めてしまい、リスクに敏感に反応しない可能性があります。
こうした状況に対して有効なのが、「アンダーサンプリング」です。これは、多数派である正常データを一部削減し、少数派であるリスクデータとの比率を調整する手法です。ただし重要なのは、闇雲に削るのではなく、どのデータを残すかを戦略的に考えることです。ここでは、ダウンサンプリングの具体的な手法としてNearMissを紹介します。
NearMiss:リスクデータと近い属性を持つ正常データを残す
多数データをランダムに削ってしまうと、リスクの微妙な兆候を含む正常ケースまで失ってしまうリスクがあります。そこで使われるのが、NearMissと呼ばれる手法です。NearMissは、「リスクデータ(少数派)に距離的に近い正常データ」を優先的に残すことを目的としています。これにより、モデルは正常と異常の境界付近の微妙な違いを学習しやすくなります。具体的には、少数派サンプルとの距離の近さによって多数派サンプルの選択を行います。
実装はimbalanced-learnというライブラリに含まれています。
こうしたアンダーサンプリングの手法は、Pythonの機械学習ライブラリとして広く使われている imbalanced-learn で利用可能です。imbalanced-learnは、さまざまなリサンプリング手法を提供しています。
imbalanced-learn:https://imbalanced-learn.org/stable/
たとえば、新規融資案件を評価するモデルを考えてみましょう。多くのケースは正常に返済されていますが、債務超過や業況悪化で返済が滞るなど返済に対する異常ケースはまれにしか存在しません。このような不均衡なデータをそのまま学習に使うと、モデルは“安全側に判断するバイアス”を強めてしまい、リスクに敏感に反応しない可能性があります。
こうした状況に対して有効なのが、「アンダーサンプリング」です。これは、多数派である正常データを一部削減し、少数派であるリスクデータとの比率を調整する手法です。ただし重要なのは、闇雲に削るのではなく、どのデータを残すかを戦略的に考えることです。ここでは、ダウンサンプリングの具体的な手法としてNearMissを紹介します。
NearMiss:リスクデータと近い属性を持つ正常データを残す
多数データをランダムに削ってしまうと、リスクの微妙な兆候を含む正常ケースまで失ってしまうリスクがあります。そこで使われるのが、NearMissと呼ばれる手法です。NearMissは、「リスクデータ(少数派)に距離的に近い正常データ」を優先的に残すことを目的としています。これにより、モデルは正常と異常の境界付近の微妙な違いを学習しやすくなります。具体的には、少数派サンプルとの距離の近さによって多数派サンプルの選択を行います。
実装はimbalanced-learnというライブラリに含まれています。
こうしたアンダーサンプリングの手法は、Pythonの機械学習ライブラリとして広く使われている imbalanced-learn で利用可能です。imbalanced-learnは、さまざまなリサンプリング手法を提供しています。
imbalanced-learn:https://imbalanced-learn.org/stable/
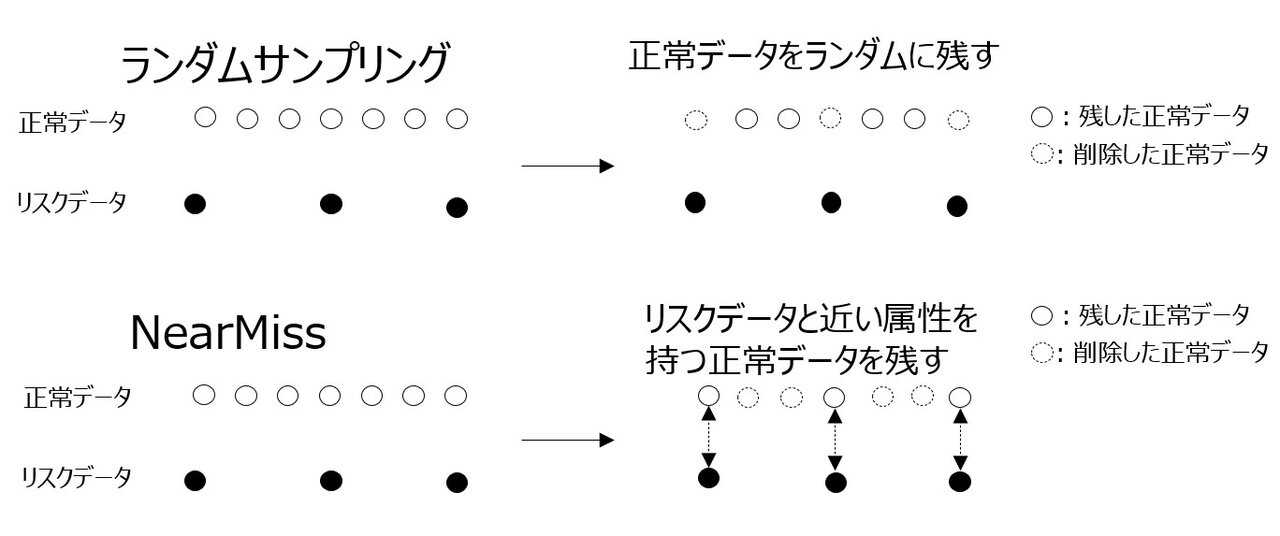
図2:アンダーサンプリングの手法
金融ユースケースに当てはめると?
たとえば、与信スコアリングモデルの学習データで多数派である“正常返済”データが多すぎる場合、モデルは単純に「返済される」と予測してしまいがちです。ここでNearMissを使うと、与信スコア境界付近の正常返済データ(たとえばクレジットヒストリーが短いが返済は続いている顧客など)を優先的に残し、モデルがリスクの兆候をより敏感に捉えるようにできます。
戦略としての位置づけ
合成データでリスクとなるデータを“増やす”だけではなく、正常データを“整理する”という発想も、ひとつ目の壁=不均衡に対して有用です。特に、学習データ全体のバランスや境界領域の情報を保つことが重要な与信・不正検知モデルの現場では、両方のアプローチを組み合わせて検討する価値があります。
たとえば、与信スコアリングモデルの学習データで多数派である“正常返済”データが多すぎる場合、モデルは単純に「返済される」と予測してしまいがちです。ここでNearMissを使うと、与信スコア境界付近の正常返済データ(たとえばクレジットヒストリーが短いが返済は続いている顧客など)を優先的に残し、モデルがリスクの兆候をより敏感に捉えるようにできます。
戦略としての位置づけ
合成データでリスクとなるデータを“増やす”だけではなく、正常データを“整理する”という発想も、ひとつ目の壁=不均衡に対して有用です。特に、学習データ全体のバランスや境界領域の情報を保つことが重要な与信・不正検知モデルの現場では、両方のアプローチを組み合わせて検討する価値があります。
合成すれば安心? ― 個人情報保護法との向き合い方
ひとつ目の壁が「不均衡」だとすれば、ふたつ目の壁は「データ共有・利用に関する制約」です。金融機関のデータ活用を語るうえで、個人情報保護法をはじめとする法制度の理解は欠かせません。
日本の個人情報保護法では、個人情報の加工形態として「匿名加工情報」と「仮名加工情報」が定義されています。
匿名加工情報は、特定の個人を識別できないように加工し、かつ復元できない状態にした情報です。一定の要件を満たせば、本人同意なしで第三者提供が可能になります。ただし、加工基準や安全管理措置など、厳格なルールが定められています。
一方の仮名加工情報は、氏名などの直接識別子を削除・置換することで、特定の個人を直ちに識別できないようにした情報です。ただし、元データと照合すれば再識別できる前提にあり、主に社内利用を想定した制度です。第三者提供には制限があります。
では、テーブルデータの「合成データ」は、これらとどのような関係にあるのでしょうか。
しばしば「合成データなら安全」と受け止められることがありますが、法的な位置づけは一律ではありません。生成方法や元データとの関係性によっては、個人情報に該当する可能性や、再識別リスクが問題になるケースも考えられます。
たとえば、元データの特徴を強く反映しすぎた合成データが生成された場合、特定の個人に関する情報が推測可能になるリスクはゼロとは言い切れません。そのため、単に「生成モデルを使った」というだけではなく、どのような加工プロセスを経たのか、再識別可能性はどの程度か、といった観点での検討が求められます。
金融機関にとって重要なのは、合成データを“抜け道”として使うのではなく、ガバナンスの枠組みのなかで位置づけることです。
技術、法務、リスク管理部門が連携し、「どの用途で、どのレベルの加工を行い、どの範囲で利用するのか」を整理する。こうした設計こそが、ふたつ目の壁を越えるための前提条件となります。
合成データは、法制度と対立する存在ではありません。むしろ、適切に設計されれば、データ活用とプライバシー保護を両立させるための選択肢のひとつになりえます。
日本の個人情報保護法では、個人情報の加工形態として「匿名加工情報」と「仮名加工情報」が定義されています。
匿名加工情報は、特定の個人を識別できないように加工し、かつ復元できない状態にした情報です。一定の要件を満たせば、本人同意なしで第三者提供が可能になります。ただし、加工基準や安全管理措置など、厳格なルールが定められています。
一方の仮名加工情報は、氏名などの直接識別子を削除・置換することで、特定の個人を直ちに識別できないようにした情報です。ただし、元データと照合すれば再識別できる前提にあり、主に社内利用を想定した制度です。第三者提供には制限があります。
では、テーブルデータの「合成データ」は、これらとどのような関係にあるのでしょうか。
しばしば「合成データなら安全」と受け止められることがありますが、法的な位置づけは一律ではありません。生成方法や元データとの関係性によっては、個人情報に該当する可能性や、再識別リスクが問題になるケースも考えられます。
たとえば、元データの特徴を強く反映しすぎた合成データが生成された場合、特定の個人に関する情報が推測可能になるリスクはゼロとは言い切れません。そのため、単に「生成モデルを使った」というだけではなく、どのような加工プロセスを経たのか、再識別可能性はどの程度か、といった観点での検討が求められます。
金融機関にとって重要なのは、合成データを“抜け道”として使うのではなく、ガバナンスの枠組みのなかで位置づけることです。
技術、法務、リスク管理部門が連携し、「どの用途で、どのレベルの加工を行い、どの範囲で利用するのか」を整理する。こうした設計こそが、ふたつ目の壁を越えるための前提条件となります。
合成データは、法制度と対立する存在ではありません。むしろ、適切に設計されれば、データ活用とプライバシー保護を両立させるための選択肢のひとつになりえます。
制約のなかで競争力を高める ― データ戦略としての合成データ
金融機関にとって、リスク管理は守りの機能であると同時に、競争力の源泉でもあります。不正を適切に防ぎ、与信判断を高度化し、将来の損失を見通す力は、顧客からの信頼と安定的な収益基盤を支えます。その中核にあるのが、データとモデルです。
しかし現実には、不均衡という構造的課題と、法制度・ガバナンスという利用制約が存在します。AI活用は、単に高度なアルゴリズムを導入すれば実現できるものではありません。どのデータを、どの目的で、どの環境で使うのか。その設計こそが問われます。
ここで重要なのは、合成データを“実データの代替”と捉えないことです。むしろ、実データを補完し、活用の幅を広げる拡張レイヤーとして位置づける視点が求められます。
たとえば、開発・検証段階では合成データを活用してモデルの方向性を素早く検討し、本番環境では厳格な管理下で実データを用いる。あるいは、部門横断の初期議論では合成データを共有し、具体的な実装段階で実データに切り替える。こうした段階的な設計は、リスクを抑えながらスピードを確保するための現実的な選択肢です。
データ戦略とは、データを「集めること」ではなく、「使い分けること」にあります。実データ、加工データ、合成データ。それぞれの特性を理解し、適切に組み合わせることができれば、制約のなかでも競争力を高めることは可能です。
合成データは、魔法の解決策ではありません。
しかし、制約を前提とした金融DXの時代において、データ活用の設計自由度を広げる一手であることは確かです。まれなリスクをどう学習させるか。その答えは、アルゴリズムの高度化だけではなく、データをどう設計するかにあります。
しかし現実には、不均衡という構造的課題と、法制度・ガバナンスという利用制約が存在します。AI活用は、単に高度なアルゴリズムを導入すれば実現できるものではありません。どのデータを、どの目的で、どの環境で使うのか。その設計こそが問われます。
ここで重要なのは、合成データを“実データの代替”と捉えないことです。むしろ、実データを補完し、活用の幅を広げる拡張レイヤーとして位置づける視点が求められます。
たとえば、開発・検証段階では合成データを活用してモデルの方向性を素早く検討し、本番環境では厳格な管理下で実データを用いる。あるいは、部門横断の初期議論では合成データを共有し、具体的な実装段階で実データに切り替える。こうした段階的な設計は、リスクを抑えながらスピードを確保するための現実的な選択肢です。
データ戦略とは、データを「集めること」ではなく、「使い分けること」にあります。実データ、加工データ、合成データ。それぞれの特性を理解し、適切に組み合わせることができれば、制約のなかでも競争力を高めることは可能です。
合成データは、魔法の解決策ではありません。
しかし、制約を前提とした金融DXの時代において、データ活用の設計自由度を広げる一手であることは確かです。まれなリスクをどう学習させるか。その答えは、アルゴリズムの高度化だけではなく、データをどう設計するかにあります。












